De nombreux développeurs Django rencontrent des difficultés avec l'optimisation des performances, non pas parce que le framework est lent, mais parce qu'ils n'exploitent pas pleinement ses fonctionnalités puissantes. Après avoir optimisé des dizaines d'applications Django en production, j'ai identifié les techniques qui apportent des améliorations réelles et mesurables. Ce guide partage 10 techniques éprouvées qui ont permis de réduire les temps de réponse jusqu'à 90% et de gérer 10 fois plus de trafic sans ajouter de serveurs.
Comprendre les Goulots d'Étranglement Courants
La plupart des applications Django sont 10 fois plus lentes qu'elles ne le devraient, non pas à cause de Django lui-même, mais à cause d'erreurs évitables. Heureusement, 90% des problèmes de performance proviennent de seulement 5 causes principales :
- Requêtes N+1 (40% des problèmes) : Un schéma de requêtes inefficace où une requête initiale entraîne l'exécution de N requêtes supplémentaires pour récupérer des données liées.
- Absence d'index (25%) : Les index sur la base de données sont cruciaux pour la rapidité de récupération des données. Sans eux, la base de données doit scanner toutes les lignes.
- Absence de mise en cache (20%) : La mise en cache permet de stocker les résultats d'opérations coûteuses pour éviter de les répéter.
- Requêtes inefficaces (10%) : Requêtes mal écrites qui récupèrent plus de données que nécessaire ou utilisent des jointures complexes inutilement.
- Fichiers statiques non optimisés (5%) : Fichiers statiques (CSS, JS, images) qui ne sont pas correctement mis en cache ou servis via un CDN.
L'optimisation prématurée, comme le disait Donald Knuth, peut être néfaste. Cependant, dans les projets matures et soumis à une charge élevée, l'optimisation devient une nécessité. En suivant une approche systématique, on peut observer des améliorations de performance de 5 à 10 fois.
Le Playbook d'Optimisation Django
1. Optimisation des Requêtes de Base de Données
C'est souvent le point le plus critique. Les jeux de résultats (querysets) dans Django sont paresseux, ce qui signifie qu'ils ne sont évalués et n'accèdent à la base de données que lorsque les données sont réellement nécessaires. Cela peut entraîner des requêtes supplémentaires lors de la sérialisation ou de l'affichage de données liées.
Le Problème des Requêtes N+1
Un exemple courant est la récupération d'une liste d'objets, puis l'accès à un champ lié pour chaque objet individuellement, générant ainsi N requêtes supplémentaires.
Exemple Négatif :
def get_posts(request): posts = Post.objects.all() # 1 requête pour les posts for post in posts: author = post.author # N requêtes supplémentaires pour chaque auteur ! print(author.name)
Pour résoudre ce problème, utilisez `select_related()` pour les relations ForeignKey et OneToOne, et `prefetch_related()` pour les relations ManyToMany et Reverse ForeignKey.
Exemple Positif :
def get_posts(request): # Utilise select_related pour les clés étrangères, une seule requête avec JOIN posts = Post.objects.select_related('author').all() for post in posts: author = post.author # Pas de requête supplémentaire ! print(author.name)Pour les relations Many-to-Many :
# Négatif : N requêtes pour les ManyToManyposts = Post.objects.all()for post in posts: tags = post.tags.all() # Requête séparée pour chaque post# Positif : Utilise prefetch_relatedposts = Post.objects.prefetch_related('tags').all()for post in posts: tags = post.tags.all() # Utilise les données mises en cacheNe Récupérer Que le Nécessaire
Par défaut, Django récupère tous les champs d'une table. Pour les tables volumineuses, il est préférable de spécifier les champs requis en utilisant `only()` ou `defer()`.
# Mauvais : Récupère toutes les colonnes, y compris les champs texte volumineuxposts = Post.objects.all()# Bon : Ne récupère que les champs requis pour la sérialisationposts = Post.objects.only('id', 'title', 'created_at')# Alternative : Exclut les champs lourdsposts = Post.objects.defer('content', 'description')# Meilleur pour des cas spécifiques : Utilise values() pour obtenir des dictionnairesposts = Post.objects.values('id', 'title')Impact Réel : L'optimisation des requêtes avec `select_related` et `prefetch_related` a réduit le temps de chargement d'un tableau de bord d'une application de 8 secondes à 0.6 secondes, soit une amélioration de 93%.
Diagnostic des Requêtes Lentes
Pour identifier les requêtes N+1 et lentes, ajoutez la configuration de logging suivante dans votre `settings.py` pour le développement :
LOGGING = { 'version': 1, 'handlers': { 'console': { 'class': 'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'level': 'DEBUG', }, },}Ceci affichera toutes les requêtes SQL dans votre console, rendant les problèmes N+1 immédiatement visibles.
2. Indexation Stratégique de la Base de Données
Les index sont essentiels pour que la base de données trouve rapidement les données. Sans eux, une recherche peut nécessiter de scanner chaque ligne.
Quand Ajouter des Index
Ajoutez des index sur les champs que vous utilisez fréquemment pour :
- Filtrer (clauses WHERE)
- Trier (clauses ORDER BY)
- Joindre (clés étrangères - auto-indexées par défaut)
Exemple :
from django.db import modelsclass Article(models.Model): title = models.CharField(max_length=200) slug = models.SlugField(unique=True, db_index=True) # Indexé published_at = models.DateTimeField(db_index=True) # Indexé author = models.ForeignKey(User, on_delete=models.CASCADE) # Auto-indexé status = models.CharField( max_length=20, choices=[('draft', 'Draft'), ('published', 'Published')], db_index=True # Indexé pour le filtrage ) content = models.TextField() # NON indexé class Meta: indexes = [ # Index composite pour les requêtes fréquentes sur plusieurs champs models.Index(fields=['status', 'published_at']), # Index pour trier par date décroissante models.Index(fields=['-published_at']), ]Index Composites
Si vous interrogez fréquemment plusieurs champs ensemble, utilisez des index composites pour améliorer les performances des requêtes combinées.
# Cette requête bénéficie d'un index composite sur status, author et published_atArticle.objects.filter(status='published', author=user).order_by('-published_at')# Ajoutez ceci à la classe Meta du modèle pour un index composite :class Meta: indexes = [ models.Index(fields=['status', 'author', '-published_at']), ]Impact Réel : Sur un site e-commerce en production, l'ajout d'un index composite sur `(category_id, price, created_at)` a réduit le temps des requêtes de liste de produits de 2.3 secondes à 0.08 secondes, soit une amélioration de 96%.
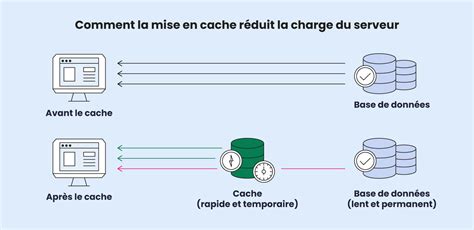
3. Mise en Cache Stratégique
La mise en cache stocke les résultats d'opérations coûteuses pour éviter de refaire le travail. Cela peut inclure la mise en cache de pages entières, de résultats de requêtes de base de données, de résultats de calculs complexes, ou même de fragments de données.
Types de Cache
- Cache de Page : Stocke la réponse HTML complète d'une vue.
- Cache de Fragment : Stocke des parties spécifiques d'un template.
- Cache de Requête : Stocke les résultats des requêtes de base de données.
- Cache d'Objet : Stocke des instances d'objets individuels.
Utilisez des solutions comme Redis ou Memcached pour un cache distribué et performant.
Exemple d'utilisation du cache de vue :
from django.views.decorators.cache import cache_page@cache_page(60 * 15) # Cache la page pendant 15 minutesdef my_view(request): # ... logique de la vue ... return render(request, 'my_template.html', context)
Impact : Une page qui servait 50 requêtes par seconde peut en gérer 400 sur le même matériel grâce à une mise en cache efficace.
4. Pool de Connexions à la Base de Données
La création de connexions à la base de données est une opération coûteuse. Le pool de connexions réutilise les connexions existantes au lieu d'en créer de nouvelles pour chaque requête.
Mise en Place avec `django-db-pool`
Installez le package :
pip install django-db-pool
Configurez votre `settings.py` :
DATABASES = { 'default': { 'ENGINE': 'django_db_pool.backends.postgresql', # Ou autre backend supporté 'NAME': 'mydb', 'USER': 'myuser', 'PASSWORD': 'mypass', 'HOST': 'localhost', 'OPTIONS': { 'MAX_CONNS': 20, # Taille maximale du pool 'MIN_CONNS': 5, # Taille minimale du pool } }}Alternative : PgBouncer (Recommandé en Production
PgBouncer est un pooler de connexions léger pour PostgreSQL, souvent préféré en production pour sa robustesse.
Installation et Configuration PgBouncer :
Installez PgBouncer (par exemple, sur Debian/Ubuntu : `sudo apt-get install pgbouncer`). Configurez le fichier `pgbouncer.ini` pour définir les bases de données et les paramètres du pool.
Configuration Django pour utiliser PgBouncer :
Configurez votre `settings.py` pour pointer vers le port de PgBouncer (par défaut 6432) au lieu du port PostgreSQL standard.
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'mydb', 'USER': 'myuser', 'PASSWORD': 'mypass', 'HOST': 'localhost', 'PORT': '6432', # Port de PgBouncer }}Impact : Amélioration de 30 à 50% dans la gestion des requêtes concurrentes.
5. Optimisation des Middlewares et Réduction de la Charge
Chaque middleware dans la pile Django ajoute un temps de traitement à chaque requête. Il est crucial d'auditer et d'optimiser cette pile.
Audit et Ordre des Middlewares
L'ordre des middlewares est important. Placez les middlewares de cache en début et fin de liste pour maximiser leur efficacité.
# settings.py - L'ordre est crucial !MIDDLEWARE = [ 'django.middleware.cache.UpdateCacheMiddleware', # 1. Middleware de cache en premier 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', 'django.middleware.cache.FetchFromCacheMiddleware', # 2. Middleware de fetch de cache en dernier]
Supprimer les Middlewares Inutiles
Si votre application n'utilise pas certaines fonctionnalités (par exemple, le framework de messages ou les sessions pour une API), supprimez les middlewares correspondants pour réduire la surcharge.
Middlewares Légers Personnalisés
Pour les API, envisagez d'utiliser des méthodes d'authentification plus légères que les sessions.
class TokenAuthenticationMiddleware: def __init__(self, get_response): self.get_response = get_response def __call__(self, request): token = request.headers.get('Authorization') if token: # Valider le token sans la surcharge de session request.user = self.get_user_from_token(token) response = self.get_response(request) return responseImpact : Amélioration de 10 à 20% de la vitesse de traitement des requêtes.
6. Pagination : Ne Pas Tout Charger
Charger des milliers d'enregistrements à la fois peut paralyser les performances. La pagination est essentielle pour limiter la quantité de données récupérées et affichées.
Pagination dans les Vues
Utilisez `django.core.paginator.Paginator` pour diviser les listes en pages.
from django.core.paginator import Paginatordef article_list(request): article_list = Article.objects.select_related('author').order_by('-published_at') # Affiche 25 articles par page paginator = Paginator(article_list, 25) page_number = request.GET.get('page', 1) articles = paginator.get_page(page_number) return render(request, 'articles/list.html', {'articles': articles})Pagination dans les API REST Framework
Configurez la pagination par défaut ou utilisez des classes de pagination spécifiques comme `CursorPagination` pour les grands ensembles de données.
# settings.pyREST_FRAMEWORK = { 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination', 'PAGE_SIZE': 20,}# Pour de grands ensembles de données, utilisez CursorPaginationfrom rest_framework.pagination import CursorPaginationclass ArticlePagination(CursorPagination): page_size = 50 ordering = '-created_at'Comptes Approximatifs
Pour de très grandes tables, `COUNT(*)` peut être lent. Utilisez des méthodes pour obtenir un compte approximatif si une précision exacte n'est pas requise pour la pagination.
# Mauvais : Exécute un COUNT(*) lent sur de grandes tablesarticle_count = Article.objects.count()# Meilleur : Compte approximatif pour la pagination (PostgreSQL)from django.db import connectiondef get_approximate_count(table_name): with connection.cursor() as cursor: cursor.execute( f"SELECT reltuples::bigint FROM pg_class WHERE relname = '{table_name}'" ) return cursor.fetchone()[0]Impact : Réduction de 80 à 95% de l'utilisation de la mémoire et du temps de requête.
7. Optimisation des Opérations en Masse
La création ou la mise à jour d'un grand nombre d'objets un par un est extrêmement inefficace. Utilisez `bulk_create()` et `bulk_update()` pour des opérations beaucoup plus rapides.
# Mauvais : 1000 requêtes INSERT individuellesfor i in range(1000): Product.objects.create(name=f'Product {i}', price=10.00)# Bon : Une seule requête INSERT avec les 1000 lignesproducts = [Product(name=f'Product {i}', price=10.00) for i in range(1000)]Product.objects.bulk_create(products, batch_size=500)# Mise à jour en masse (Django 2.2+)products_to_update = Product.objects.filter(category='Electronics')for product in products_to_update: product.price *= 1.1 # Augmentation de 10% du prixProduct.objects.bulk_update(products_to_update, ['price'], batch_size=500)Opérations en Masse avec Retour de Valeurs :
Depuis Django 4.0, `bulk_create()` peut retourner les objets créés et gérer les conflits.
# Django 4.0+ pour bulk_create avec retour et gestion des conflitsproducts_data = [Product(name=f'Product {i}', price=10.00) for i in range(100)]created_products = Product.objects.bulk_create( products_data, batch_size=50, ignore_conflicts=True, # Ignore les doublons update_conflicts=True, # Met à jour en cas de conflit update_fields=['price'], unique_fields=['sku'])Impact Réel : L'importation de 10 000 enregistrements avec `create()` a pris 45 secondes. L'utilisation de `bulk_create()` avec `batch_size=1000` a terminé en 0.8 secondes, soit une amélioration de 56 fois.
8. Optimisation des Fichiers Statiques et CDN
Les fichiers statiques (CSS, JavaScript, images) peuvent considérablement ralentir le chargement des pages s'ils ne sont pas gérés correctement.
Utilisation de WhiteNoise
WhiteNoise est un package qui simplifie le service des fichiers statiques en production, même sans serveur web dédié comme Nginx.
Installez WhiteNoise :
pip install whitenoise
Ajoutez-le à votre `MIDDLEWARE` dans `settings.py` :
MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'whitenoise.middleware.WhiteNoiseMiddleware', # Ajoutez ceci # ... autres middlewares ...]
Utilisation d'un CDN (Content Delivery Network)
Pour une performance maximale, servez vos fichiers statiques via un CDN. Cela distribue vos fichiers sur des serveurs dans le monde entier, réduisant la latence pour les utilisateurs.
Impact : Amélioration de 40 à 60% du temps de chargement des pages.
9. Profilage et Surveillance Réguliers
On ne peut pas optimiser ce que l'on ne mesure pas. Mettez en place un système de surveillance continue pour identifier les goulots d'étranglement dès qu'ils apparaissent.
Django Silk pour le Profilage en Développement
Django Silk est un outil utile pour profiler les requêtes en développement.
Installez Silk :
pip install django-silk
Ajoutez-le à `INSTALLED_APPS` et `MIDDLEWARE` dans `settings.py`.
Outils de Profilage Python
Utilisez le profileur intégré de Python (`cProfile`) ou des outils tiers pour analyser la performance du code en détail.
Surveillance en Production
Utilisez des outils comme Sentry, Datadog, New Relic, ou Prometheus/Grafana pour surveiller les performances de votre application en production.
Présentation de Django Debug Toolbar Autoreload
10. Mise à Jour des Packages et de Django
Chaque nouvelle version de Python et Django apporte souvent des améliorations de performance, de sécurité et de nouvelles fonctionnalités.
Maintenez vos dépendances à jour, mais testez toujours les mises à jour avant de les déployer en production.
Impact : Les nouvelles versions sont généralement plus efficaces, mais il faut mesurer pour confirmer les gains spécifiques à votre cas.
Cas d'Étude : Optimisation d'une Plateforme E-commerce
Une plateforme e-commerce Django rencontrait des problèmes de performance importants :
- État Initial :
- Chargement de la page d'accueil : 4.2 secondes
- Liste des produits : 6.8 secondes
- Gestion d'environ 50 utilisateurs concurrents
- Utilisation moyenne du CPU du serveur : 85%
- Optimisations Appliquées :
- Requêtes de base de données : Ajout de `select_related` et `prefetch_related`.
- Index : Ajout d'index composites sur les champs fréquemment interrogés.
- Mise en cache : Implémentation de Redis pour la mise en cache des listes de produits.
- Fichiers statiques : Passage à un CDN avec WhiteNoise.
- Pagination : Limitation des produits à 24 par page.
- Pool de connexions : Implémentation de PgBouncer.
- Résultats Finaux :
- Chargement de la page d'accueil : 0.3 secondes (amélioration de 93%)
- Liste des produits : 0.5 secondes (amélioration de 92%)
- Gestion d'environ 500 utilisateurs concurrents (augmentation de 10x)
- Utilisation moyenne du CPU du serveur : 35% (réduction de 60%)
Ces améliorations ont été réalisées sans changer le matériel ni ajouter de serveurs.
Erreurs Courantes à Éviter
- Optimisation prématurée : N'optimisez pas avant d'avoir mesuré. Profilez d'abord pour identifier les goulots d'étranglement.
- Cache excessif : Mettre en cache tout peut entraîner des problèmes de données obsolètes. Cachez de manière stratégique.
- Ignorer les index de base de données : Ce sont des gains de performance gratuits, souvent négligés.
- Ne pas tester avec des données de production : Testez avec des volumes de données réalistes. 100 enregistrements se comportent différemment de 100 000.
- Optimiser les mauvaises choses : Une amélioration de 50 ms sur une page de 100 ms est moins importante qu'une amélioration sur une page de 5 secondes. Concentrez-vous d'abord sur les problèmes majeurs.
tags: #django #50 #performance #debride